Apple och University of Washington testar AI-agenter på Gemini och ChatGPT, slutsats: teknologin är inte redo ännu

Medan vi alla aktivt testar hur AI kan skriva uppsatser, koda eller generera bilder, har forskare från Apple och University of Washington ställt en mycket mer praktisk fråga: vad skulle hända om vi gav artificiell intelligens full tillgång till hantering av mobilapplikationer? Och kanske viktigast av allt, kommer den att förstå konsekvenserna av sina handlingar?
Vad som är känt
Studien med titeln "Från interaktion till påverkan: Mot säkrare AI-agenter genom att förstå och utvärdera påverkan av mobil UI-operationer", publicerad för IUI 2025-konferensen, har ett team forskare identifierat en allvarlig brist:
Moderna storskaliga språkmodeller (LLMs) förstår gränssnitt ganska bra, men de är katastrofalt dåliga på att förstå konsekvenserna av sina egna handlingar i dessa gränssnitt.
Till exempel ser det ut som om AI, när den klickar på knappen "Ta bort konto", nästan exakt gör samma sak som "Gilla". Skillnaden mellan dem behöver fortfarande förklaras för den. För att lära maskiner att särskilja mellan vikten och riskerna med handlingar i mobilapplikationer har teamet utvecklat en speciell taksonomi som beskriver tio huvudsakliga typer av påverkan av handlingar på användaren, gränssnittet och andra människor, och tar även hänsyn till reversibilitet, långsiktiga konsekvenser, utförandeverifiering och till och med externa kontexter (till exempel geolokalisering eller kontostatus).
Forskningen skapade en unik datamängd med 250 scenarier där AI behövde förstå vilka handlingar som är säkra, vilka som behöver bekräftelse, och vilka som helst inte bör utföras utan en människa. Jämfört med de populära datasetten AndroidControl och MoTIF är den nya uppsättningen mycket rikare i situationer med verkliga konsekvenser, från shopping och lösenordsändringar till smart hemhantering.
En webgränssnitt för deltagare att generera åtgärdsspår av ett gränssnitt med influenser, inklusive en mobiltelefonskärm (vänster) och inloggnings- och inspelningsfunktioner (höger). Illustration: Apple
Studien testade fem språkmodeller (LLMs) och multimodala modeller (MLLMs), nämligen:
- GPT-4 (textversion) - en klassisk textversion utan att arbeta med gränssnittsbilder.
- GPT-4 Multimodal (GPT-4 MM) är en multimodal version som kan analysera inte bara text utan också gränssnitts bilder (till exempel skärmdumpar av mobilapplikationer).
- Gemini 1.5 Flash (textversion) är en modell från Google som arbetar med textdata.
- MM1.5 (MLLM) är en multimodal modell från Meta (Meta Multimodal 1.5) som kan analysera både text och bilder.
- Ferret-UI (MLLM) är en specialiserad multimodal modell tränad specifikt för att förstå och arbeta med användargränssnitt.
Dessa modeller testades i fyra lägen:
- Zero-shot - ingen ytterligare träning eller exempel.
- Knowledge-Augmented Prompting (KAP) - med tillägg av kunskap om taksonomin för åtgärdspåverkan till prompten.
- In-Context Learning (ICL) - med exempel i prompten.
- Chain-of-Thought (CoT) - med prompts som inkluderar steg-för-steg resonerande.
Vad visade testerna? Även de bästa modellerna, inklusive GPT-4 Multimodal och Gemini, uppnår en noggrannhet på just över 58% i att bestämma nivå av påverkan av handlingar. Den sämsta AI:n klarar inte av nyanserna av typen av reversibilitet av handlingar eller deras långsiktiga effekt.
Intressant nog tenderar modellerna att överdriva riskerna. Till exempel, GPT-4 kunde klassificera rensning av historiken på en tom kalkylator som en kritisk åtgärd. Samtidigt kunde vissa allvarliga åtgärder, såsom att skicka ett viktigt meddelande eller ändra finansiella data, undervärderas av modellen.
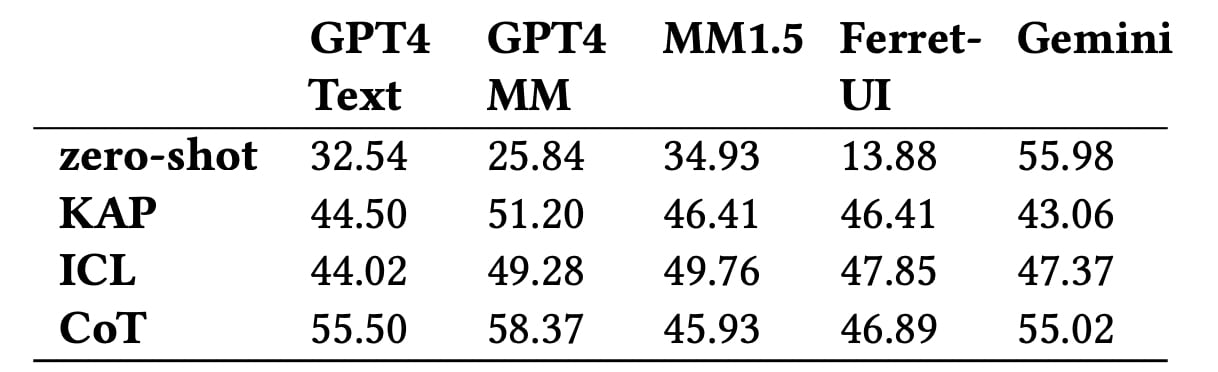
Noggrannheten av att förutsäga den övergripande nivån av påverkan med olika modeller. Illustration: Apple
Resultaten visade att även toppmodeller såsom GPT-4 Multimodal når inte 60% noggrannhet i klassificeringen av nivån av påverkan av handlingar i gränssnittet. De har särskilt svårt att förstå nyanser som reversibilitet av handlingar eller deras påverkan på andra användare.
Som resultat drog forskarna flera slutsatser: först, mer komplexa och nyanserade metoder för kontextförståelse krävs för att autonom AI-agenter ska kunna fungera säkert; för det andra kommer användarna att behöva ställa in nivån av "försiktighet" av sin AI på egen hand i framtiden - vad som kan göras utan bekräftelse och vad som absolut inte är tillåtet.
Denna forskning är ett viktigt steg mot att säkerställa att smarta agenter i smartphones inte bara trycker på knappar, utan också förstår vad de gör och hur det kan påverka människor.
Källa: Apple